ES 的限制和疑难问题
Programmers know the benefits of everything and the tradeoffs of nothing.
程序员知道任何事情的收益,却不去权衡利弊
Relational Databases Aren’t Dinosaurs, They’re Sharks - Simple Thread
背景
使用关系型数据的思想去操作 ES,会发现很多功能的实现和想象中有出入
或者 ES 能够实现很多操作,但同时又有很多限制,在解决了一些问题基础上(天然分布式适合大数据量、top hit 这种方便的功能、模糊搜索分词器),是否也引入了一些新问题
记录下 ES 难以处理的问题以及当前的处理方法,是否可以有更好的处理方式,或者选型中避免处理此类问题
深度分页
ES 作为天然的分布式系统,数据分散至各个 shard 进行存储
带来的问题就是随着分页深度的增加,成本的增加也会更加明显
ES 假设一页有 100 条数据,需要查询第 100 页数据(即 from = 9900,size = 100),那么对于每一个节点都需要查询 10000 条数据,汇总给协调节点后,再有协调节点排序,最终选取真实命中的 100 条数据返回
所以对于深度分页 ES 进行了限制,默认的配置是 from + size < 10000,大于限制的查询操作会被拒绝
现在是怎么处理的
没有好的办法,限制跳页的深度,如果需要查询更精准的数据就增加查询条件来缩小范围
业务绝大多数场景应该也没有查看这么多页数据的必要
可以使用 search after、scroll 避免深度分页限制,但是都有各自场景的限制
索引刷新间隔
索引下会有一个参数值 refresh_interval,表示 ES
刷新索引的间隔
刚进行索引的文档并不会立即对搜索可见,而是满足一定的要求后才会将
buffer 中的数据建立索引写入文件区,其中 refresh_interval
参数指定一定的时间间隔后将数据进行索引
refresh_interval 的单位:
- ms
- s
- m
单位缺省值为 ms,如果配置为 -1
则表示不刷新索引,当需要导出大量数据时,可以将
refresh_interval 设置为 -1
加快导入速度,导入完成后再设置刷新间隔或者手动刷新
设置 refresh_interval
1 | PUT /{index}/_settings |
强制刷新
1 | POST {index}/_doc?refresh |
现在是怎么处理的
根据业务情况合理设置刷新间隔,需要兼顾 ES 压力和数据实时性要求,暂时配置的 500 ms
但是 scroll + update by doc id 的更新方式是否会因为 scroll 的快照特性和索引刷新时间问题而导致数据错误?这种情况怎么避免
不及时刷新也会导致 update by query 操作冲突
根据条件更新 update by query
update by query 操作看起来类似 SQL 中的
UPDATE FROM ... SET ... WHERE ...,但使用起来也有很多限制
更新内容使用 script 指定,例如,姓名为 张三 的数据 age +
1
1 | POST my-index/_update_by_query |
因为 ES 的锁机制比较简单,对于冲突只能选择两种操作
conflicts(Optional, string) What to do if update by query hits version conflicts:
abortorproceed. Defaults toabort.
同时需要进行手动刷新,否则可能会频繁冲突
refresh(Optional, Boolean) If
true, Elasticsearch refreshes affected shards to make the operation visible to search. Defaults tofalse.
此外,ES 客户端和服务端是通过 REST 进行交互,连接时间是存在限制的,默认是 30 s
当脚本具有一定的处理逻辑,并且数据量较大,很有可能在限制时间内没有处理完成,就会抛出超时异常
现在是怎么处理的
配置连接时间,减少更新的文档数量,每次写入都进行更新
list 字段增删元素
ES mapping 中字段是不限制元素数量的(感觉和索引的实现方式有关)
例如
1 | GET /my-index/_mapping |
数据可以是
1 | { |
那么在更新 list 字段时就需要考虑更新方式,如果是刷新文档进行覆盖,会不会出现数据错误?
假设一个操作要给字段增加一个元素 1,而另一个操作要删除元素 2
| 时间 | 线程 1 | 线程 2 |
|---|---|---|
| T1 | 查询文档数据 doc,得到 field = [2,3] | / |
| T2 | 处理得知,需要写入的数据 field = [1,2,3] | 查询文档数据 doc,得到 field = [2,3] |
| T3 | 写入 ES,field = [1,2,3] | 处理得知,需要写入的数据 field = [3] |
| T4 | / | 写入 ES,field = [3] |
最终导致数据错误(没有 DB 的锁机制那么方便)
update by query
当然可以使用 update by query 来使用脚本进行操作,相当于把一部分运算逻辑放在了 ES 来执行
1 | POST my-index/_update_by_query |
现在是怎么处理的
使用 update by query 脚本进行增删,配置连接时间,限制更新的数据量(时间作为条件)
折叠、聚合不支持滚动查询
scroll,search after 可以不受深度分页的限制,现在的客户端对于 scroll 操作包装的比较简单(没法指定数据集 size),并且一次性取出所有数据进入内存
所以使用 search after 来实现对更大量数据的查询(导出)
但折叠(Collapse)和聚合(Aggregations)操作无法支持 scroll 或者 search after 的查询方式
现在是怎么处理的
对于折叠或者聚合的数据使用分页进行查询,无法避免深度分页的限制
聚合桶数量限制
ES 的聚合从功能上可以分为 3 类:
- 桶聚合(Bucket):对数据进行分组(分桶);类似
GROUP BY- Date histogram 日期直方图
- Range 范围
- Terms 字段值
- ...
- 指标聚合(Metric):对桶内数据进行指标的计算;类似聚合函数
- Avg 平均数
- Max 最大值
- Sum 求和
- ...
- 管道聚合(Pipeline):以其他聚合作为元数据的聚合;相当于在其他聚合的基础上再次进行操作
- Bucket selector 桶选择器
- Bucket sort 桶排序
- Max bucket 最大的桶
- ...
桶聚合中最常见的场景就是根据字段值进行分桶(相当于
GROUP BY 多个字段)
但是 ES 中对于桶的数量是有限制的,当一次请求超过桶数量限制(默认为
123),则查询会返回错误
trying to create too many buckets. must be less than or equal to: [100000] but was [100001]
这是 6.x 以后版本的特性, 目的是限制大批量聚合操作, 规避性能风险
当然可以进行配置,但也就意味着可能承担更多的性能风险
1 | PUT /_cluster/settings |
桶聚合的 size
同时,桶聚合需要指定 size 参数,也就是说 ES
并不会直接计算出所有的桶
假设 size 设置为
1000,此时数据中根据某个维度分桶有 1500
个,那么 ES 只会选择 top 1000 个桶进行返回
现在是怎么处理的
对于桶聚合的
size,给定一个较大的值,在短期内应该不会出现这么桶,如果超出限制则由查询逻辑手动进行桶的划分,同时业务是不是业务要思考,需不需要关注一个维度数据下所有值的结果(比如只关注
top 的数据)
对于桶数量显示,使用默认值,定时聚合中间结果(牺牲实时性,对查询有利),聚合过程中可以手动拆分聚合维度来减少桶的数量
聚合后排序和分页
聚合后是无法按照文档内字段顺序来进行排序的(这点在关系型数据库中应该也是如此),但是 ES 的折叠操作可以按照文档顺序进行
聚合后的排序肯定只能通过聚合维度来进行排序(桶聚合的 key
或者指数聚合的结果),排序和分页的实现使用管道聚合中的
Bucket sort 实现
1 | POST /sales/_search |
上述操作:
- 对日期按月进行桶聚合
- 对
price字段进行sum的指数聚合 - 对桶聚合进行排序和分页,按照指数聚合
total_sales结果倒序,取 3 条数据
这里会出现一个问题,如果是嵌套的桶聚合,bucket_sort
是无法对上层桶,或者对全局的桶进行分页操作
ES 文档原文 Bucket sort aggregation | Elasticsearch Guide [8.5] | Elastic
The
bucket_sortaggregation, like all pipeline aggregations, is executed after all other non-pipeline aggregations. This means the sorting only applies to whatever buckets are already returned from the parent aggregation. For example, if the parent aggregation istermsand itssizeis set to10, thebucket_sortwill only sort over those 10 returned term buckets.
在关系型数据库中,假设对 A、B 字段进行聚合操作,然后在其基础上进行分页后有 5 条数据
A - 1、A - 2、B - 1、B - 2、B - 3
那么使用 bucket_sort 分页后,假设
from = 0,size = 1
理想情况下是只返回 A - 1 这一条
但因为只对 parent 桶有效,实际的返回会是
A - 1 和 B - 1,因为 size 只限制了 B
字段分桶的桶数量
摘自网络 https://blog.csdn.net/weixin_29715563/article/details/112106227
张超大佬指出:分析系统里跑全量的 group by 我觉得是合理的需求, clickhouse 很擅长做这种事,es 如果不在这方面加强,分析场景很多会被 clickhouse 替掉
腾讯大佬指出:聚合这块比较看场景。因为我这边有一些业务是做聚合,也就是 olap 场景,多维分析,ES 并不是特别擅长,如果有丰富的多维分析场景,还有比较高的性能要求。我建议可以调研下 clickhouse。我们这边测评过开源和内部的大部分场景 clickhouse 几十亿的级别,基本也在秒级返回甚至毫秒级
Kibana 是怎样实现的
在 Kibana 上配置图表,看起来能直接实现很类似的功能
并且还支持跳页,不过看了其请求,在刷新时直接进行了一次大请求,返回了所有数据,最后应该是在内存中进行的分页操作
所以看起来 ES 的聚合本身就无法支持嵌套分页的操作
现在是怎么处理的
使用默认值,定时聚合中间结果(牺牲实时性,对查询有利),就可以根据中间结果进行分页了,业务也需要考虑是否有必要跳页,聚合后的结果是动态的、非直观的,跳页查询还有意义吗
同时对于嵌套聚合、折叠的场景,拼接一个用于聚合的 key 作为聚合字段(相当于业务数据手动拼接一个 key,使一层聚合实现嵌套聚合的效果,只能针对固定需求,丧失了灵活性)
桶聚合准确性
ES 的桶聚合会由各个分片聚合出结果后再交由协调节点汇总数据(也就是此时汇总数据是没有全局视野的),可能会导致桶的不准确
这个参数由桶聚合的 shard_size 进行控制,默认取值为
size × 1.5 + 10
也就是每个节点只会聚合 shard_size
大小的结果返回给协调节点,再有协调节点合并结果,返回出 size
所需数量的桶(可以看出 shard size 不可能小于
size)
也就是最终结果的桶并不是绝对准确的,需要合理设置
shard_size 平衡准确性和性能
现在是怎么处理的
因为聚合桶数量限制,size
设置了一个短期来看足够大的值,所以 shard_size 同样很大
应该暂时不会存在桶不准确问题
基数聚合准确性
因为分页展示的要求,对于聚合或者折叠后,需要统计桶的数量
嵌套操作无法进行基数聚合,所以此处也使用了业务手动拼接的聚合
key,进行 cardinality 操作
1 | POST /sales/_search?size=0 |
需要注意的是,基数聚合虽然可以统计出基数,但底层使用 HyperLogLog 进行实现,也就是带有一定的误差
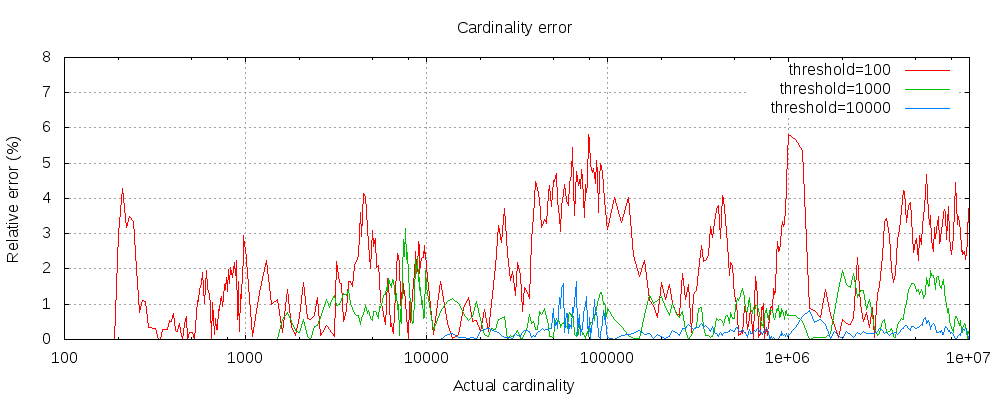
误差是比较小的,即使阈值低至 100,即使在百万 + 基数时,误差仍然很低(如上图所示,为1 - 6%)
允许误差存在会导致最终总页数不准确,或者每次查询都有所区别
不过 cardinality 支持精度参数
precision_threshold,如果基数数量在指定精度以内,那么就不存在误差
1 | POST /sales/_search?size=0 |
现在是怎么处理的
因为本身 ES 就有深度分页的限制(默认
10000),所以对于基数聚合也指定了
precision_threshold = 10000
这样对于基数 10000 以内的数据会返回精确值,超过 10000 就不需要关注精确的值,只向前端返回 10000 限制跳页深度