规则引擎简单介绍
介绍
如果你一直在开发一种产品或业务,那么经常发生的场景就是不断变化的业务需求;开发人员基于一组条件构建解决方案,随着时间的推移,这些逻辑条件可能会因业务需求或其他外部市场因素的变化而发生改变
规则引擎是解决此类问题的有效方法
Guide to Rule Engines – Mohit Khare
美团外卖的 CRM 业务步入成熟期,规则类需求几乎撑起了这个业务所有需求的半边天;一方面规则唯一不变的是 “多变”,另一方面开发团队对 “规则开发” 的感受是乏味、疲惫和缺乏技术含量
如何解决规则开发的效率问题,最大化解放开发团队成为目前的一个 KPI
什么是规则引擎
业务规则引擎是在执行一个或多个业务规则的系统,这些规定可能来自各种业务规则:
- 员工可以因任何原因或无原因被解雇,但不能因非法原因
- 所有一次性消费超过 100 美元的客户都将获得 10% 的折扣
业务规则系统使这些倾向于运营决策、公司策略的规则能够与应用程序代码分开定义、测试、执行和维护;规则集用于检查条件并选择合适的业务执行操作
规则可以简单抽象为如下结构
1 | When |
例如一个提供折扣优惠的规则
条件:当用户满足以下所有条件时
- 至少下单过 10 个订单
- 平均订单价格大于 150 元
- 用户年龄在 20 ~ 30
行为:提供 20% 的折扣
规则引擎在解决面向业务的逻辑时比较有效,这些逻辑使用许多业务属性来产生某种决策
难道我们不能把这个逻辑嵌入我们的代码中吗?可以这样做,但规则化提供了修改条件和添加更多逻辑的灵活性;这些条件也许更多来由产品或业务产出,这会让它们更加容易变更,也许不需要由开发人员进行修改
优点
grule-rule-engine: Rule engine implementation in Golang Advantages of a Rule Engine
- 声明式编程(Declarative Programming):规则可以很容易地表达难题的解决方案并进行验证;与代码不同,规则是用不那么复杂的语言编写的;业务分析师可以很容易地阅读和验证一套规则
- 逻辑和数据分离(Logic and Data Separation):数据驻留在域对象中(Domain Objects),业务逻辑驻留在规则中(Rules);根据项目的类型,这种分离可能非常有利
- 知识集中化(Centralization of Knowledge):通过使用规则,您可以创建一个可执行的知识库(a repository of knowledge | a knowledge base);这是商业政策的唯一真理;理想情况下规则是可读的,因此它们也可以作为文档
- 改变的敏捷性(Agility To Change):由于业务规则实际上被视为数据,根据业务的动态性质调整规则变得微不足道;不需要像正常的软件开发那样重新构建代码或部署,只需要推出规则集并将其应用于知识库即可
使用案例
grule-rule-engine: Rule engine implementation in Golang use-cases
使用规则引擎可以更好地解决以下情况:
- 专家系统(Expert System):必须评估事实以提供某种现实世界的结论;如果不使用 RETE 风格的规则引擎,就会编写一组 If/else 语句的级联集,而如何评估这些语句的组合的排列将很快变得无法管理
- 评级系统(Rating System):例如银行系统可能希望根据客户的交易记录(事实)为每个客户创建一个 “分数”;我们可以根据他们与银行互动的频率、进出资金的多少、支付账单的速度、累计利息的多少、为自己或银行赚了多少等等来查看他们的分数变化,随后银行客户分析部门的专家可以来提供事实和规则的说明
- 电脑游戏:玩家状态、奖励、惩罚、伤害、分数和概率系统是规则在大多数电脑游戏中发挥重要作用的许多不同例子
- 分类系统(Classification Systems):使用规则引擎,我们可以对信用资格、生物化学识别、保险产品风险评估、潜在安全威胁等进行分类
- 建议系统(Suggestion System):“规则” 只是另一种数据,这使它可以成为另一个程序的产出;这个程序可以是另一个专家系统或人工智能,规则可以由其他系统操纵以便处理关于规则集针对业务域新建模型来处理新的事实
还有许多其他用例将受益于规则引擎的使用,上述情况只是潜在情况中的一小部分
不过规则引擎当然不是银弹,存在许多替代方案来解决软件中的 “知识” 问题,并且应该在最合适的地方使用这些替代方案;例如如果一个简单的 if/else 分支就足够了,那么就不需要使用规则引擎
还有一点需要注意:一些规则引擎实现非常昂贵,但许多企业从中获得了如此多的价值,以至于运行它们的成本很容易被这些价值所抵消;对于即使是中等复杂的场景,强大的规则引擎对于解耦团队并解决业务复杂性也有显著的优势
开源生态
Drools
Drools - Documentation Drools 使用基于规则的编程模型,允许开发人员通过编写规则来描述应用程序中的业务逻辑
特点:
- 基于规则的编程模型:Drools 使用规则引擎来编写业务规则,允许开发人员将业务逻辑从应用程序中分离出来,使其更加灵活和易于维护
- 支持多种规则格式:包括 DRL(Drools 规则语法 | Drools Rule Language)、DSL(领域特定语法 | Domain Specific Language),支持 OMG1 标准下的 DMN(决策模型与符号 | Decision Model and Notation) ,甚至数据领域 DMG2 标准的 PMML(预测模型标记语言 | Predictive Model Markup Language)
- 多语言支持:Drools 不仅支持 Java 语言,还支持其他编程语言如 Python 等
- 完善的生态:Drools 下生态丰富,涉及多种工具
- Drools Engine:核心 Drools 规则引擎
- Drools and jBPM integration:规则引擎 Drools 和工作流 jBPM 整合
- Business Central Workbench3:可视化工作台
- KIE Execution Server:可用于使用 REST、JMS 或 Java 接口远程执行规则的独立执行服务器
- 规则插件:DRL 规则文件插件高亮
缺点:
开源 Drools 从入门到放弃 ——《从0到1:构建强大且易用的规则引擎 - 美团技术团队 (meituan.com)》
- 业务分析师无法独立完成规则配置:由于规则主体 DSL 是编程语言(支持 Java, Groovy, Python 等),因此仍然需要开发工程师维护
- 规则规模变大以后也会变得不好维护,相对硬编码的优势便不复存在
- 规则的语法仅适合扁平的规则,对于嵌套条件语义(
then中嵌套whenthen子句)的规则只能将条件进行笛卡尔积组合以后进行配置,不利于维护
备注
OMG 是Object Management Group的缩写,是一个国际性的技术标准组织,成立于 1989 年,总部位于美国马萨诸塞州的 Needham。OMG 的成员包括软件和硬件供应商、工具提供商、服务提供商、企业和政府机构等,旨在推动和制定面向对象技术的标准和规范 About the Decision Model and Notation Specification Version 1.4 (omg.org)
Data Mining Group(DMG)是一个非营利性组织,成立于 1994 年,旨在推动数据挖掘和知识发现技术的发展和应用。DMG 的成员包括数据挖掘和机器学习领域的专家、学者和工业界代表,致力于制定和推广数据挖掘标准和规范
Business Central Workbench GUI

LiteFlow
可以将瀑布流式的代码,转变成以组件为核心概念的代码结构,这种结构的好处是可以任意编排,组件与组件之间是解耦的,组件可以用脚本来定义,组件之间的流转全靠规则来驱动
特点:
- 语法简单:组件由 Java(硬编码)或支持的脚本语言进行开发,规则 DSL 语法定义简单,符合 Spring 等 IOC 框架的容器思想,易于理解
- 流程图式编排:规则描述使用流程图模式,而不是 Drools
的
when...then模式,让特定流程的任务编排更加清晰、灵活 - 并发编排:规则逻辑可以快速编排组件之间的同步、异步关系,可以自定义执行线程池
- 丰富的脚本组件支持:支持多种脚本语言(Groovy,Javascript,QLExpress,Python,Lua,Aviator);采用 SPI 机制进行选择脚本框架来动态编译脚本;同时支持规则文件内多脚本语言混合使用
- 多数据源和热刷新:EL
规则和脚本组件都支持多种数据源(项目内文件、本地文件、ZK、SQL、Nacos、Apollo
等数据源),同时支持自定义实现相关规则解析类
ClassXmlFlowELParser等;支持平滑热刷新 - 补充功能丰富:有丰富的小功能支持
- 声明式组件
- 前置、后置组件、组件切面
- 组件重试
- 异常、步骤信息汇总
- 规则插件:同样拥有规则高亮插件支持,也支持脚本语法高亮
官方介绍:LiteFLow 介绍 PPT
缺点:
- 缺乏大范围生产考验,社区迭代速度和成熟产品相比较慢
- 流程图式编排使组件规则调整需要考虑前后关系
- 生态不完全,没有管理平台、可视化编排工具
Ice
开源框架学习与分享 | ice (waitmoon.com)
Ice 使用全新的设计思想,契合解耦和复用的属性,满足最大的编排自由度
特点:
- 独特的规则编排思想:引入关系节点的与或非控制流程,在一些场景下可以更好的对流程进行控制,避免流程前后的组件影响,降低心智负担
- 组件的时间属性:组件天然带有时间属性,可以控制执行组件生效的时间范围(对于活动类配置非常有用)
- 组件参数:组件参数由 Json 格式的数据进行配置,对于同样的组件不同的参数不需要从业务入口或进行中的 Context 进行控制
- 可视化后台配置:拥有可视化后台配置,对规则和节点进行配置 ice配置后台 (waitmoon.com)
官方介绍:ice 编排逻辑
缺点:
- 新项目,热度低,案例少
- 文档简陋
Aviator
killme2008/aviatorscript: A high performance scripting language hosted on the JVM. (github.com)
严格来说 AviatorScript 并不是一个规则引擎,而是一个可以编译为 Java 字节码的表达式引擎
在美团的技术文章中使用该脚本语言作为规则框架使用(具体怎么实现也看不懂,可能是因为支持自定义函数)
AviatorScript 的优势
高性能:将表达式直接翻译成对应的 Java 字节码执行,编译优先模式只扫一遍,保证了性能超越绝大部分解释性的表达式引擎
轻量级:其次,除了依赖
commons-beanutils这个库之外(用于做反射)不依赖任何第三方库,因此整体非常轻量级,整个 jar 包大小哪怕发展到现在 5.0 这个大版本,也才 430K开放能力:Aviator 内置的函数库非常节制,除了必须的字符串处理、数学函数和集合处理之外只能自定义函数实现,保证了安全性
特色:
支持运算符重载
原生支持大整数和
BigDecimal类型及运算,并且通过运算符重载和一般数字类型保持一致的运算方式原生支持正则表达式类型及匹配运算符
=~类
clojure的seq库及 lambda 支持,可以灵活地处理各种集合
美团文章中使用 Aviator 对函数的扩展
自定义函数可以扩充 Aviator 功能,规则引擎可通过自定义函数执行因子及规则条件
如调用用户画像等第三方服务
| 名称 | 示例 | 含义 |
|---|---|---|
| equals | equals(message.orderType, 0) | 判断订单类型是否为 0 |
| filter | filter(browseList, 'source', 'dp') | 过滤点评侧浏览列表数据 |
| poiPortrait | poiPortrait(message.poiId) | 根据 poiId 获取商户画像数据,如商户星级属性 |
| userPortrait | userPortrait(message.userId) | 根据 userId 获取用户画像数据,如用户常住地城市、用户新老客属性 |
| userBlackList | userBlackList(message.userId) | 根据 userId 判断用户是否为黑名单用户 |
Grule
hyperjumptech/grule-rule-engine: Rule engine implementation in Golang (github.com)
Grule 是 Go(Golang)编程语言的规则引擎库,灵感来自广受好评的 JBOSS Drools,并以更简单的方式完成
与 Drools 一样,Grule 也有自己的 DSL 或领域特定语言
应用情况
- 美团 从0到1:构建强大且易用的规则引擎
- 美团技术团队 大数据:美团酒旅实时数据规则引擎应用实践
- 外卖业务绩效指标
- 美团点评酒旅实时触达
- 京东 履约核心引擎低代码化原理与实践
- 掘金
- 订单生产履约
- 货拉拉 货拉拉大数据基于规则引擎构建运力资源供需调节系统
- 大数据,运力供需平衡
- 雪球 规则引擎在内容管理中的探索与应用
- 内容风控
- 陌陌 momosecurity/aswan:
陌陌风控系统静态规则引擎,零基础简易便捷的配置多种复杂规则,实时高效管控用户异常行为。
(github.com)
- 用户风控
各种工具、云服务其实也离不开各种规则配置
Octopus 告警规则 
Sentry Alert Rule 
阿里云物联网平台
阿里云物联网平台 - 设置数据流转规则 (aliyun.com)
CDN
规则编排思想
规则引擎的核心之一就在于规则的编排方式,上面的开源框架、工具都有其不同的规则编排思想
这里就单独聊一聊不同工具的不同规则表达
when ... then
代表:Drools、Grule
when ... then
是最典型的规则编排思想,一组规则由两部分组成:
- LHS(Left Hand Side):条件分支逻辑
- RHS(Right Hand Side):执行逻辑
The
whenpart of a DRL rule (also known as the Left Hand Side (LHS) of the rule) contains the conditions that must be met to execute an action.The
thenpart of the rule (also known as the Right Hand Side (RHS) of the rule) contains the actions to be performed when the conditional part of the rule has been met.
Drools 规则
1 | rule "SpeedUp" |
Grule 规则
1 | rule SpeedUp "When testcar is speeding up we keep increase the speed." salience 10 { |
when ... then
的形式适合大量事实对象进入然后进行大量规则的匹配、执行操作
整个规则是平铺式的,可以使用表格来进行展示(下面就要提到 Drools 的决策表机制)
不适合处理带有流程性的规则
决策表 树
代表:Drools
决策表其实就是另一种形式的 when ... then
表达,之间可以互相转换;此外 Drools
还支持非常多的规则形式,在这里列举一部分 Drools
Documentation#Authoring rule assets
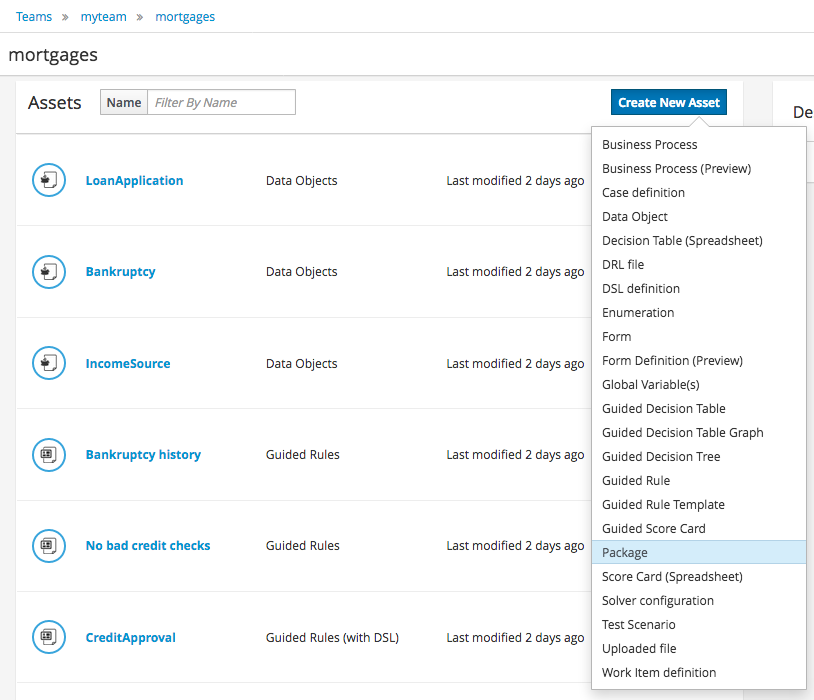
电子表格决策表
Spreadsheet decision tables
电子表格决策表是包含以表格格式定义的业务规则的 XLS 或 XLSX 电子表格
决策表中的每一行都是一条规则,每一列都是一个条件、一个操作或另一个规则属性;创建并上传电子表格决策表后,定义的规则将与所有其他规则资产一样被编译为 DRL 规则

上面的决策表例子转换为 DRL 格式的规则文件内容如下:
1 | package rules.excels; |
引导式决策表
Guided decision tables
Drools 支持两种类型的决策表:扩展条目表(Extended entry)和有限条目表(Limited entry)
扩展条目表:扩展条目决策表是列定义指定 Pattern、Field 和 Operator 但不指定值的决策表。值或状态本身保存在决策表的主体中

有限条目表:除了 Pattern、Field 和 Operator 之外,Limited Entry 决策表的列定义还为其指定值 决策表状态保存在表的主体中,是布尔值,其中 true 具有应用或匹配列的效果;false 表示该列不适用

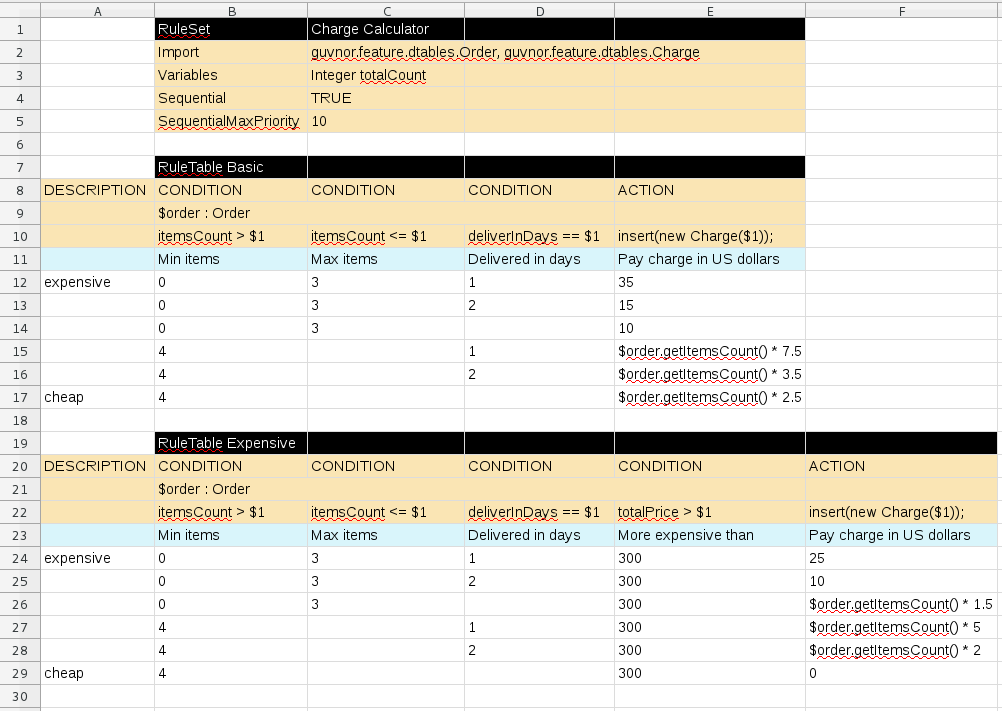
引导式决策图
虽然可以编写单个引导决策表,但也可以编写相关表的图,其中一个表的动作可以提供另一个表条件的潜在匹配,在这种情况下表被认为是相关的
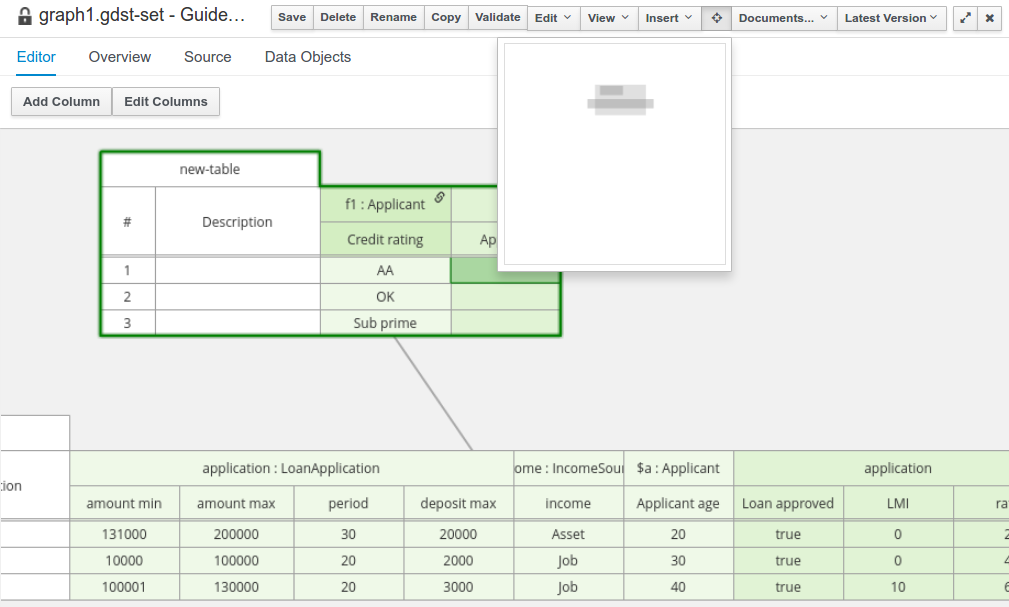
引导式决策树
Business Central 支持编写简单的决策树
http://49.235.87.129:8080/business-central
流程图
代表:LiteFlow
LiteFlow 的规则语法相当于构造出一个流程图,组件作为节点,规则描述组件间执行关系:
- 串行
THEN - 并行
WHEN - 选择
SWITCH - 条件
IF - 循环
- for 循环
FOR...DO - while 循环
WHILE...DO - 迭代器循环
ITERATOR...DO - 跳出
BREAK
- for 循环
- 异常捕获
CATCH - 异或非表达
AND、OR、NOT

1 | <chain name="chain1"> |
使用子变量优化
1 | <chain name="chain1"> |
关系控制
代表:ice
流程图式和执行树式实现的主要缺点在于,牵一发而动全身,改动一个节点需要瞻前顾后,如果考虑不到位,很容易弄错,而且这还只是一个简单的例子,现实的活动内容要比这复杂的多的多,时间线也是很多条
往往得不偿失,到头来发现还不如硬编码
Ice 的规则编排强调组件生效时间和规则之间的关系
Ice 中分为两种规则节点:
- 关系节点:关系节点为了控制业务流转
- AND:
&&,在执行到 false 的地方终止执行 - ANY:
||,在执行到 true 的地方终止执行 - ALL:所有子节点都会执行,根据节点返回值进行不同的返回
- NONE:所有子节点都会执行,无论子节点返回什么都返回 none
- TRUE:所有子节点都会执行,无论子节点返回什么,都返回 true
- AND:
- 叶子节点:叶子节点为真正处理的节点
- Flow:一些条件与规则节点,如例子中的 ScoreFlow
- Result:一些结果性质的节点,如例子中的 AmountResult,PointResult
- None:一些不干预流程的动作,如装配工作等
文档中有一个例子来体现这样编排规则的优势:
X 公司将在国庆放假期间,开展一个为期七天的充值小活动,活动内容如下:
- 活动时间(10.1 - 10.7)
- 活动内容
- 充值 100 元 送 5 元余额 (10.1 - 10.7)
- 充值 50 元 送 10 积分 (10.5 - 10.7)
- 不叠加送(充值 100 元只能获得 5 元余额,不会叠加赠送 10 积分)

需要对规则进行调整:
充值 100 元改成 80,10 积分变 20 积分,时间改成 10.8 号结束
去掉不叠加送
5 元余额不能送太多,设置个库存 100 个;库存不足充 100 元还是得送 10 积分

优势:
- 对于 1
的改动,只需要修改节点逻辑(
ScoreFlow、PointResult) - 对于 2 的改动将入口的关系节点 ANY 修改为 ALL
- 对于 3 由于库存的不足,相当于没有给用户发放,则
AmountResult返回 false,流程还会继续向下执行,不用做任何更改 - 引入 ALL 节点及
TimeChangeNone来修改时间,方便测试
思考:规则引擎到底是什么形式
Drools 或者传统的规则引擎倾向于大量业务规则下的匹配,所以也被称为决策(Decision)引擎
而 LiteFlow 更像是设计模式的延伸,组件的执行编排,但是也称为 “规则引擎”
一些概念
DSL
DSL(Domain Specific Language,领域特定语言)是一种专门用于解决特定领域问题的编程语言,它是一种特定领域的专用语言,通常具有简单、易用、高效等特点;DSL 的语法和语义通常与特定领域的问题密切相关,可以大大简化问题的表达和解决
这里以 Drools 为例,Drools 可以根据定义的 DSL 文件和 DSLR 文件,将其转换为 DRL 表达
DSL
1 | [<scope>][<type definition>]<dsl expression>=<replacement text> |
1 | [when] There is a person = $p:Person() |
DSLR
这样整个 DSLR 文件讲使用语义化的表达来描述存在 DSL 定义的特定领域内规则
1 | rule 'test-dsl' |
转换后的 DRL 规则
1 | rule 'test-dsl' |
DMN
DMN 全称 Decision Model and Notation(决策模型与符号),是一种用于表示业务决策和规则的规范,旨在帮助参与决策的人都能简单快速理解决策过程
DMN 是由 OMG 管理的一种规范,该组织下比较知名的还有 UML 等
Drools 对 DMN 有良好的支持,支持 DMN 1.3,功能完善
Learn DMN in 15 minutes | Introduction (learn-dmn-in-15-minutes.com)

DMN 中支持 FEEL 规则表达式
足够友好的表达语言(Friendly Enough Expression Language )FEEL 表达式定义了 DMN 模型中决策的逻辑,FEEL 旨在通过为决策模型结构分配语义来促进决策建模和执行
DMN FEEL handbook – Drools DMN FEEL handbook (kiegroup.github.io)
CEP
CEP 是复杂事件处理(Complex event processing)的缩写
事件是某个时间点应用程序域中状态发生重大变化的记录,根据域的建模方式,状态的变化可以由单个事件、多个原子事件或相关事件的层次结构表示
从复杂事件处理(CEP)的角度来看,事件是发生在特定时间点的一种事实或对象,而业务规则是如何对来自该事实或对象的数据做出反应的定义:例如在股票经纪人应用程序中,证券价格的变化、所有权从卖方到买方的变化或账户持有人余额的变化都被视为事件,因为在给定时间应用程序域的状态发生了变化
Drools 中的 Drools engine 使用复杂事件处理(CEP)来检测和处理事件集合中的多个事件,揭示事件之间存在的关系,并从事件及其关系中推断新数据
CEP 场景具有以下关键特征:
- 场景通常处理大量事件,但只有一小部分事件是真正关心的
- 事件通常是不可变的,因为它们是状态改变的一条记录(是一个历史状态)
- 规则和查询针对事件运行,并且必须对检测到的事件模式作出反应
- 相关事件通常具有很强的时间关系
- 独立的事件是不重要的;CEP 系统优先考虑相关事件的模式及其之间的关系
- 事件通常需要组合和聚合
鉴于这些常见的 CEP 场景特征,Drools 中的 CEP 系统支持以下特性和功能,以优化事件处理:
- 具有适当语义的事件处理
- 事件检测、关联、聚合和合成
- 事件流(Event stream)处理
- 对事件之间的时间关系建模的时间约束
- 事件滑动窗口
- 会话范围的统一时钟
- 反应式规则
- 用于事件输入到 Drools 引擎的适配器
声明事件
1 | declare VoiceCall |
Drools 对于 CEP 有着丰富的时间规则支持
在流模式下,Drools 引擎对工作内存的事件支持以下时态运算符:
afterbeforemeetsduring- ...
以 after 为例
$eventA : EventA(this after[3m30s, 4m] $eventB) 或者
3m30s <= $eventA.startTimestamp - $eventB.endTimeStamp <= 4m
表示:如果 $eventA 在 $eventB 结束后 3 分
30 秒到 4 分之间开始,则以下模式匹配;如果 $eventA 在
$eventB 结束后 3 分 30 秒之前开始,或在
$eventA 结束后 4 分钟之后开始,则不匹配
时间 长度滑动窗口
- 处理最后 2 分钟的库存点(时间滑动窗口)
StockPoint() over window:time(2m) - 处理最后10个库存点(长度滑动窗口)
StockPoint() over window:length(10)
例如以下两个 DRL 规则根据平均温度激活火灾警报;第一条规则使用滑动时间窗口来计算最后 10 分钟的平均值,而第二条规则使用滚动长度窗口来计算最近一百个温度读数的平均值
1 | rule "Sound the alarm if temperature rises above threshold" |
1 | rule "Sound the alarm if temperature rises above threshold" |
行为型模式
Behavioral design patterns are concerned with algorithms and the assignment of responsibilities between objects.
行为模式负责对象间的高效沟通和职责委派
对于流程图式规则,我认为是行为模式的扩展,将分支组件选择同样进行了组件化
策略

策略模式(Strategy Pattern)定义了一系列算法,并将每个算法封装起来,使它们可以相互替换,从而使得算法可以独立于使用它们的客户端而变化
策略模式的优点:
- 在于它可以提高代码的灵活性和可维护性。它可以使得算法与客户端分离,从而使得客户端不需要了解算法的具体实现细节
- 策略对象可以在运行时动态地切换,使得客户端可以根据不同的情况选择不同的策略对象,从而实现更加灵活的算法组合和配置
- 将不同行为抽取到一个独立类层次结构中, 并将原始类组合成同一个, 从而减少重复代码(便于模板)
- 组合代替继承
- 符合开闭原则,无需对上下文进行修改就能够引入新的策略
责任链

责任链模式(Chain of Responsibility Pattern)通过将请求发送给一系列处理对象,使得每个处理对象都有机会处理请求,从而实现请求的处理与发送者的解耦
责任链模式的优点:
- 将复杂的处理逻辑分解为多个简单的处理对象,使得代码更加清晰易懂
- 可以控制请求处理的顺序
- 满足单一职责原则,可对发起操作和执行操作的类进行解耦
- 符合开闭原则,可以在不更改现有代码的情况下在程序中新增处理者
流水线

管道设计模式(Pipeline Pattern)将一个复杂的任务分解为多个独立的阶段,每个阶段都由一个独立的处理器来完成,并且处理器之间通过管道进行连接,从而形成一个处理流程
流水线模式的优点:
- 将复杂的任务分解为多个独立的阶段
- 流程编排,可以复用逻辑节点
- 提高代码的可重用性和可测试性,因为每个处理器都可以单独测试和调试
- 可以利用多核处理器的优势,提高代码的并发性能
核心能力
这里列举了一些规则引擎的核心机制
对于 Drools 支持的能力主要结合文档进行简单的介绍,对于 LiteFlow 等支持的能力会结合源码
规则编排
Drools 使用了 RETE 算法的变体 Phreak 来做为规则算法
LiteFlow 使用了 alibaba 开源的 QLExpress 作为规则的解析工具(QLExpress 也是一款表达式引擎,或者说是脚本语言)
1 | ExpressRunner runner = new ExpressRunner(); |
因为 QLExpress 还支持扩展操作符,所以被 LiteFlow 用来解析其 DSL 定义的规则
1 |
|
1 | flow: |
最终的 EL THEN(a, b, WHEN(c, d)) 都是交由 QLExpress
进行处理
LiteFlowChainELBuilder#setEL
1 | public LiteFlowChainELBuilder setEL(String elStr) { |
静态成员 EXPRESS_RUNNER 即为 QLExpress 提供的
ExpressRunner 实例
在静态代码块中初始化扩展操作符
1 | /** |
扩展操作符的实现就是构建 LiteFlow 最终的节点抽象
Executable 的抽象实现 Condition
BaseOperator 为了强化 executeInner
方法,会捕获抛出的 QLException 异常,输出友好的错误提示
1 | public class ThenOperator extends BaseOperator<ThenCondition> { |
最终就到了规则对象封装的三个类型
- Executable
- Condition:条件对象,核心属性
executableGroup,持有ExecutableMap - Chain:规则链对象,核心属性
conditionList,持有Condition集合 - Node:Node 节点,核心属性
NodeComponent,才是组件执行的核心
- Condition:条件对象,核心属性
最终在 FlowExecutor 执行中获取 Chain
为入口,进行执行
1 | try { |
并发编排
LiteFlow
中的流程图式规则表达天然支持灵活地对执行任务进行并发控制,使用关键词
WHEN 进行表达
1 | <chain name="chain1"> |
表示串行执行节点 a,随后并行执行节点 b、c、d,最后继续串行执行节点 e
同时拥有一些拓展功能:
- 忽略错误:
WHEN(b, c, d).ignoreError(true)当 b、c、d 节点出现异常时进行忽略 - 任意执行成功:
WHEN(b, THEN(c, d), e).any(true)当 b、并行的 c 和 d、e 任意执行成功则继续向下执行 - 分组:
THEN(WHEN(a, b),WHEN(c, d))关键词WHEN天然具有分组概念
并发的第一步,整个规则被包装为 WhenCondition 对象
1 | public class WhenCondition extends Condition { |
对象中包括 WHEN 规则相关的属性,以及关键的
executeCondition 实现
实现中调用了 executeAsyncCondition
executeAsyncCondition
代码比较长,概括做了以下几件事:
- 拿到
Condition下的可执行元素的集合executableGroup,过滤掉前后置组件(PreCondition和FinallyCondition)以及Node的isAccess为 false 的节点(这里是为了处理一个 bug issue:关于when和then混合使用时(有any和isAccess的情况下),then的节点先执行的问题 · Issue #I4XRBA · dromara/liteFlow - Gitee.com) - 使用
ScheduledThreadPoolExecutor实现CompletableFuture异步处理超时,将Executable数据包装为ParallelSupplier,调用CompletableFuture.supplyAsync - 根据
any参数使用CompletableFuture.anyOf或CompletableFuture.allOf,拿到封装流程后的resultCompletableFuture - 执行
resultCompletableFuture.get进行阻塞,catchInterruptedException - 拿到已经完成的结果,对未完成的任务进行过滤(如果
any为 true,那么这里拿到的是第一个完成的任务) - 过滤出超时的任务,输出超时日志
- 根据参数
isIgnoreError,处理InterruptedException;遍历CompletableFuture的返回值,如果异步执行失败,则抛出相应的业务异常
执行组件
Drools 中没有组件的概念,但是每个规则表达中 then
部分直接调用 Java 代码或者由 MVEL 或 Java 定义执行逻辑
1 | import com.example.User; |
LiteFlow 中的组件由 Java 代码编写(也可以脚本组件),可以作为 bean 接入 Spring
FlowParse 及其实现

FlowExecutor 的 init 方法
1 | // 查找对应解析器 |
NodeType 节点类型
1 | public enum NodeTypeEnum { |
整体流程:
- 文件解析(XML、JSON)
NodePropBean包装- buildNode,FlowBus 添加节点元数据
- 如果是声明式组件,Spring 环境下已经是代理对象则不处理,非 Spring
环境执行
LiteFlowProxyUtil.proxy2NodeComponent - 配置组件,new Instance
- 如果是声明式组件,Spring 环境下已经是代理对象则不处理,非 Spring
环境执行
- 脚本组件,加载 script 脚本
脚本组件
在 Drools 中本身的规则表达就是 Drools 定义的类 Java 语法,同时也支持 DMN 的 FEEL 等语法,相当于脚本语言
在 LiteFlow 中支持多种脚本语言来定义组件:
- Groovy
- Javascript
- QLExpress
- Python
- Lua
- Aviator
1 |
|
NodeComponent 实现类 loadScript
1 | public class ScriptCommonComponent extends NodeComponent implements ScriptComponent { |
ScriptExecutorFactory.loadInstance().getScriptExecutor(language).load(getNodeId(), script)
主要获取了 ScriptExecutor 的实现

groovy 的 ScriptEngine 由 groovy-jsr223 依赖提供
org.codehaus.groovy.jsr223GroovyScriptEngineImpl
最终编译为 CompiledScript 实现,存储至
compiledScriptMap
1 | public abstract class JSR223ScriptExecutor extends ScriptExecutor { |
思考:
- 业务中应该有多少脚本、表达式引擎的应用?
- 什么场景适合 or 不适合?
XXL-Job 支持的 GLUE 模式
规则热更新
规则配置的热更新是规则化的重要优势,特别是很多成熟的规则引擎都提供了 GUI 后台
Drools 支持的规则读取方式:
KieClasspathContainer项目 resource 文件KieBuilder项目外文件KieScanner仓库 jar 包(Workbench)
Drools 的更新方式:
- 使用
KieContainerImpl.updateToKieModule - 创建新的
KieContainer - 使用
InternalKnowledgeBase的 API;粒度更细,注意规则切换非原子性带来的影响
LiteFlow 的规则本质是一个执行链(Chain 和
Condition),在执行时会 copy
出一份新的执行链对象,所以对于规则的热更新应该是天然支持平滑的
即你可以在不重启服务的情况下,进行规则的重载
并且在高并发下刷新的时候,正在执行流程的线程是完全平滑的,不会因为刷新的过程而出现中断的现象
在刷新时,正在执行的流程还是走的旧的流程;刷新好,后续 request 会自动切换到新的流程
LiteFlow 规则更新的方式:
在 Spring 容器中拿到
FlowExecutor对象调用flowExecutor.reloadRule()指定刷新某一个 Chain 的规则
1
2
3LiteFlowChainELBuilder.createChain().setChainName("chain2").setEL(
"THEN(a, b, WHEN(c, d))"
).build();配置放在中间件,利用中间件的配置监听机制进行更新
- ZK
- Etcd
- SQL(Java.sql)
- Nacos
- Apollo
核心原理就是定义各自数据源的
Parse,在解析方法中执行监听操作、挂载监听相关的回调
(不过我发现对于远程规则的配置都是全量刷新,相当于每次变更重新加载整个规则文件,不像本地规则文件一样可以配置多个?)
1 | public class NacosXmlELParser extends ClassXmlFlowELParser { |
本地文件监听使用了 Apache commons.io 的
FileAlterationMonitor
1 | observer.addListener(new FileAlterationListenerAdaptor() { |
reloadRule 操作的本质是重新进行
FlowExecutor 的 init
操作,看起来也是直接刷新所有文件规则,粒度较粗
决策控制
Drools 在面对大量规则时更好的规划命中的规则(规则冲突、优先级、循环等),支持规则下一些参数控制匹配规则的行为 Execution control in the Drools engine
在 Java 应用程序中第一次调用 fireAllRules 后,Drools
引擎会在两个阶段重复循环:
- 事项评估(Agenda evaluation):在这个阶段,Drools 引擎选择所有可以执行的规则;如果不存在可执行规则,则执行周期结束;如果找到了可执行规则,Drools 引擎会在议程中注册激活,然后进入工作内存行为阶段,执行规则后果操作
- 工作内存行为(Working memory
actions):在这个阶段,Drools
引擎为之前在事项中注册的所有激活规则执行规则后果操作(每个规则的
then行为部分);在所有结果操作完成或主 Java 应用程序进程再次调用fireAllRules后,Drools 引擎返回到议程评估阶段以重新评估规则
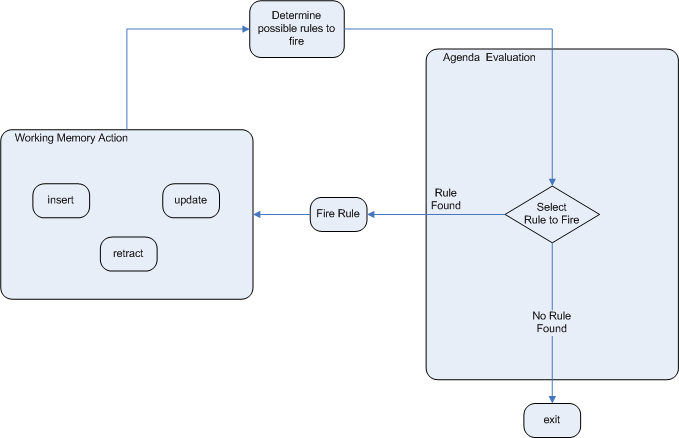
当事项(agenda)上存在多个规则时,执行一个规则可能会导致从议程中删除另一个规则;为了避免这种情况可以定义 Drools 引擎中执行规则的方式和时间
规则优先级 Salience for rules
每个规则都有一个确定执行顺序的整数优先级属性;当在激活队列中排序时,具有较高优先级值的规则被赋予更高的执行优先级
规则的默认优先级为 0,但优先级可以设置为负数或正数
1 | rule "RuleA" |
RuleB 规则列在下面,但它的优先级值高于 RuleA 规则,因此首先执行
规则事项组 Agenda groups for rules
事项组是由同一事项组规则属性绑定在一起的一组规则
在任何时候,只有一个组的焦点使该组规则优先于其他事项组中的规则执行;可以通过对议程组的
setFocus 调用来确定焦点
还可以定义具有 auto-focus
属性的规则,以便下次激活规则时,将焦点自动分配给规则所分配的整个议程组
1 | rule "Increase balance for credits" |
1 | rule "Print balance for AccountPeriod" |
例如,report
事项组中的规则必须始终首先执行,calculation
事项组的规则必须总是其次执行;然后可以执行其他议程组中的任何剩余规则
因此,在执行其他规则之前,report 和
caclulation 组必须按该顺序接收要执行的焦点:
1 | Agenda agenda = ksession.getAgenda(); |
规则激活组 Activation groups for rules
激活组是由相同的激活组规则属性绑定在一起的一组规则
在该组中只能执行一个规则;在满足执行该组中的规则的条件后,将从事项中删除该激活组中的所有其他挂起的规则执行
1 | rule "Print balance for AccountPeriod1" |
1 | rule "Print balance for AccountPeriod2" |
在示例中执行了 report
激活组中的其中一条规则,则第二条规则不会执行
执行模式和线程安全 Rule execution modes and thread safety in the Drools engine
- 被动模式(Passive mode):当用户或应用程序显式调用
fireAllRules时,Drools 引擎会评估规则
1 | KieSessionConfiguration config = KieServices.Factory.get().newKieSessionConfiguration(); |
- 活动模式(Active mode):如果用户或应用程序调用
fireUntilHalt,Drools 引擎以活动模式启动并不断评估规则,直到用户或应用程序显式调用halt
1 | KieSessionConfiguration config = KieServices.Factory.get().newKieSessionConfiguration(); |
事实传播模式 Fact propagation modes in the Drools engine
Drools 引擎支持以下事实传播模式,这些模式决定 Drools 引擎如何通过引擎网络处理插入的事实,为规则执行做准备:
- 惰性(Lazy):(默认)事实在规则执行时以批处理集合的形式传播,而不是实时传播,因为事实是由用户或应用程序独立设置的;因此事实最终通过 Drools 引擎传播的顺序可能与单独插入事实的顺序不同(没有顺序性)
- 立即(Immediate):事实会按照用户或应用程序插入的顺序立即传播
- 迫切(Eager):事实是延迟传播的(在批处理集合中),但在规则执行之前
Drools 引擎将这种传播行为用于活动属性上
no-loop或lock-on-active的规则
默认情况下,Drools 引擎中的 Phreak 规则算法使用惰性事实传播来改进总体规则评估;但是在少数情况下这种惰性传播行为可能会改变某些规则执行的预期结果,这些规则执行可能需要 Immediate 或 Eager 传播
1 | query Q (Integer i) |
1 | KieSession ksession = ... |
该规则仍然会被命中,因为默认的 Lazy 传播失去了顺序
在这种情况下,要更改 Drools 引擎传播模式以实现预期的规则评估,可以将
@propagation(<type>)标记添加到规则中,并将
<type> 设置为 LAZY、IMMEDIATE 或 EAGER
1 | query Q (Integer i) |
事项评估过滤器 Agenda evaluation filters
Drools 引擎支持过滤器接口中的 AgentaFilter
对象,可以使用该对象在事项评估期间允许或拒绝对指定规则的评估
可以指定一个议程过滤器作为 fireAllRules 调用的一部分
以下示例代码只允许评估和执行以字符串 “Test” 结尾的规则;所有其他规则都会从 Drools 引擎事项中过滤掉
1 | ksession.fireAllRules( new RuleNameEndsWithAgendaFilter( "Test" ) ); |
LiteFlow 中对于组件的流程也有其控制机制
虽然整个组件是通过 EL 表达式编排起来,但是可以重写
Component 相关的方法进一步进行流程控制
isAccess 推荐实现 isAccess
方法,表示是否进入该节点,可以用于业务参数的预先判断
这里官方文档写的比较简单;上面提过 Executable 其中有
Node 和 Component 的实现
- 对于
Node而言,isAccess控制该组件是否执行,但是不会影响后续组件的执行 - 对于
Condition,因为后续流程需要由Condition来进行控制,例如SwitchCondition、IfCondition,所以对于Condition相关的组件isAccess为 false 则该路线不会向下执行了
isEnd 如果覆盖后,返回 true,则表示在这个组件执行完之后立马终止整个流程
对于这种方式,由于是用户主动结束的流程,属于正常结束,所以最终的
isSuccess 为 true
beforeProcess & afterProcess
流程的前置和后置处理器,其中前置处理器,在 isAccess
之后执行
所有组件通用的前后切面可以使用切面组件
ICmpAroundAspect;Spring 环境下也可以使用 Spring Aspect
onSuccess & onError
流程的成功失败事件回调
简单应用
价格计算
LiteFlow 有一个 Demo 案例,可以简单了解是如何使用的
通知文案
tutor-student-notify 对于发送逻辑的处理
产品曾经提过理想中的产品使用,GUI 配置、文案编辑,不需要研发参与修改;不过现实还是比较复杂的,这里使用 LiteFlow 实现一个 Demo
(具体的代码就不粘贴在这里了)
设计的组件:
- initContextCmp:初始化上下文
- lessonInfoCmp:Lesson 信息获取
- userInfoCmp:User 信息获取
- teacherInfoCmp:Teacher 信息获取
- lowGradeJudgeCmp:
IF节点,判断是否是低年级 - templateKeySelectCmp:通用模板 key 选择模板,将 key 写入
Context,需要组件参数
- 组件参数:模板 key
- customerHotlineCmp:客服电话参数
- 组件参数:客服电话配置
- userNameParamCmp:用户昵称参数
- lessonNameParamCmp:班课名称参数
- 组件参数:占位符 name 和求值表达式
- sendCmp:发送
规则 EL
1 | <flow> |
现有业务 - 退课退款
tutor-lesson-order 服务中对于退款流程的处理,感觉很接近流程式规则的思想
- Pipeline、组件化、组件编排
- 并发编排
- Context 设计和工作台模式
上下文
RefundContext 是其退款业务上下文的基类

以实物商品退款流程上下文
PhysicalCommodityRootRefundContext 为例
- PhysicalCommodityRootRefundContext:实物商品
- UnboxedRootRefundContext:非盒子
- OrderItemEO
- LessonDigest
- LessonOrderEO
- partRefund
- refundQuantity
- code
- extraMap
- StandardRootRefundContext:基础退款数据
- baseParam
- refundConfig
- refundTs
- bizRefundInfoMap
- mergedRefundInfo
计算节点产出的新对象为 NestedContext 实现类,依靠
BaseNestedRefundContext 进行连接
1 | public class BaseNestedRefundContext implements NestedContext { |
执行链
执行链的核心类是 RefundPipeline
组链操作由 RefundPipelineService 提供
RefundTask 实现类的 bean,RefundPipelines
作为工具类,提供 RefundTaskGroupConfig 映射真实的 bean
以及最后的组装
1
2
3
4
5
6
7
8
9
10private static List<RefundTask[]> groupTasks(List<RefundTask> allTasks, RefundTaskGroupConfig groupConfig) {
return groupConfig.keySet().stream().sorted().map(groupId -> {
Collection<String> taskNames = groupConfig.get(groupId);
return allTasks.stream()
.filter(task -> taskNames.contains(task.getName()))
.collect(Collectors.toList())
.toArray(new RefundTask[]{});
}).collect(Collectors.toList());
}
计算节点 & 执行节点
unboxed 班课退款流程
- 加载节点 & 计算节点 Pipeline
- 【0】base info loader
- unboxed_base_ctx_loader
- 【1】biz loader
- gift_order_loader
- textbook_refund_loader
- dual_coupon_loader
- marketing_activity_refund_loader
- 【100】biz calculator
- gift_order
- dual_coupon
- lesson_textbook
- marketing_activity_refund_calc
- 【101】
- lesson_agenda
- 【1000】merge calculator
- merge_refund
- 【0】base info loader
- 执行节点 Pipeline
- 【0】
- refund_lesson_order
- 【1】
- 【2】
- gift_order_post
- lesson_order_delivery
- record_refund
- dual_coupon_post
- marketing_activity_refund_post
- 【0】
思考:组件化后如何保证编排的正确性
如上,如果执行节点被配置到了计算节点之前会出现问题;作为工作台模式,总之具有前后顺序的组件顺序错误就会导致流程的错误
1. 组件间解耦,但还是需要注意组件之间的流程编排
2.如何对组件的编排进行校验
任务 / 并发编排
RefundTaskGroupConfig 用来描述任务配置
private final Map<Integer, Collection<String>> configValue;
其属性 configValue 的 key 用来描述并发分组即顺序,value
为 RefundTask bean name 的集合
RefundTaskGroup 用来封装并发编排的任务
RefundTaskGroup
- tasks:
RefundTask集合,包含了当前 group 需要并发执行的任务 - pipeline:
RefundPipeline和RefundTaskGroup互相持有
为什么这个地方 group 需要持有 pipeline 节点?因为 task 被 group 持有,context 被 pipeline 持有,而 task 的运行需要 context
整个 pipeline 模式下对象之间的关系

LiteFlow DSL
上述业务对节点的编排相当于 LiteFlow 中的 WHEN 和
THEN
如果表示为流程图

如果使用 LiteFLow 的 EL 表示
1 |
|
AI 结合思考
自从今年 AI 成为热题后,各界都在考虑如何使用 AI 提供新产品、提高生产力
AI 技术可以帮助程序员更快地完成一些繁琐、重复性的任务,如代码审查、测试、调试等;此外,AI 还可以通过自动化一些流程和工作流程来简化开发流程,从而提高生产效率
而规则引擎的规则编排、甚至是脚本语法相比逻辑代码由 AI 辅助我认为更适合,甚至实现上可能更简单:
- 规则编排有时由业务、产品、数据进行编写,不能使用复杂的开发语言;可以使用自然语言描述 AI 转换规则
- 规则往往被限定在一个较小的业务范围内,AI 所需的上下文较少,结果更加准确
- AI 是否可以避免规则冲突、流程定义错误的人工错误
Drools DRL & CEP
问:
我将会给一段自然语言描述,将其转换为 Drools 的 DRL 规则
每当 BuyOrder 事件发生时,等待匹配的 AckOrder 事件 10s 的时间,如果匹配成功,则发送短信给用户
答:
下面是将自然语言描述转换为 Drools DRL 规则的示例代码:
1 | import java.util.concurrent.TimeUnit; |
在这个规则中,我们首先导入了 Java 中的 TimeUnit 类,用于指定等待 10 秒的时间
然后我们定义了一个名为 "Match AckOrder and Send SMS" 的规则,其中:
- 当 BuyOrder 事件发生时,使用 not 关键字等待 10 秒来匹配 AckOrder 事件
- 如果在 10 秒内成功匹配到 AckOrder 事件,则将会执行 then 语句
- 在 then 语句中,我们使用 $buyOrder 对象的 getPhoneNumber() 方法获取用户的电话号码,并将消息发送给用户
阅读 DRL 规则
问:
我将会给你一段 Drools DRL 规则,请用中文描述这段规则的含义
1 | rule "Underage" |
答:
这段 Drools DRL 规则的含义是:
当规则引擎匹配到一个名为 LoanApplication 的对象,并且其中的 Applicant 对象的 age 属性小于 21 岁时,就会触发这个规则
该规则的优先级为 15,它属于 agenda-group "applicationGroup" 组
触发规则后,规则引擎会将 $application 对象的
approved 属性设置为
false,表示不批准该贷款申请;同时,它会将 $application
对象的 explanation 属性设置为
Underage,表示不批准该贷款申请的原因是申请人未达到法定年龄
自然语言辅助生成 DSL 规则
问:
我将会使用语言描述规则,帮我生成 Drools DSL 文件
- 当用户购买商品为促销商品,并且用户为普通会员,则打印日志 “当前用户为普通会员”,行为是商品价格打 9 折
- 当用户购买商品为促销商品,并且用户为黄金会员,则打印日志 “当前用户为普通会员”,行为为商品价格打 8 折
答:
根据你的要求,将上述场景转换为带有表达式转换的形式,可以得到如下的 Drools DSL 文件:
1 | [when] There is a purchase = $p:Purchase() |
DSLR
1 | rule 'discount_standard_user' |
阅读 LiteFlow 流程图式 EL
问:
我设计如下语法:
THEN表示串行;如TEHN(A,B,C)表示执行 A 后执行 B,最后执行 CWHEN表示并行;如WHEN(A,B)表示 A 和 B 是并行的;WHEN(A,then(B,C))表示 A 和 B、C 之间的执行是并行的,B 和 C 的执行是串行的SWITCH表示选择,会根据返回值对下一个执行的组件进行选择;如SWITCH(A).to(B,C,D),会执行组件 A,根据返回值决定后面的流程是执行 B 或者 C 或者 DIF表示判断,会根据返回的布尔类型选择下一个执行的组件;如IF(A,B,C),执行组件 A,如果返回值是 true 则执行 B,如果返回值是 false 则执行 C;如果是IF(A,B),则 false 时不会执行
上述所有的关键词支持嵌套
现在我将会给你一段由上述语法组成的表达式,帮我用自然语言描述所进行的操作
1 | THEN( |
答:
这个表达式描述了一个程序的执行流程,按照以下步骤执行:
- 首先执行
unboxed_base_ctx_loader组件 - 接着执行两个并行的组件序列,第一个并行序列包括
gift_order_loader、textbook_refund_loader、dual_coupon_loader、marketing_activity_refund_loader和lesson_extra_loader这些组件,这些组件会同时执行;第二个并行序列包括gift_order、dual_coupon、lesson_textbook和marketing_activity_refund_calc这些组件,这些组件也会同时执行 - 执行
lesson_agenda组件 - 最后执行
merge_refund组件
需要注意的是,第一个并行序列中的所有组件都需要在第一个步骤中执行完毕后才能开始执行,而第二个并行序列中的所有组件都需要在第一个并行序列中的组件全部执行完毕后才能开始执行;另外,执行
marketing_activity_refund_calc 组件的前提是执行
dual_coupon 和 gift_order 组件,而执行
merge_refund 组件的前提是执行所有其他组件
参考
博客
官方文档
技术文章
开源软件
其他